



The introduction of Pre-trained Language Models (PLMs) has signified a transformative shift in the field of Natural Language Processing. They have demonstrated exceptional proficiency in performing a wide range of language tasks, including Natural Language Understanding (NLU) and Natural Language Generation (NLG). These models typically incorporate millions or even billions of parameters, leading to substantial computational and memory requirements. However, the considerable computational and memory needs of these models present significant challenges, as acknowledged by the research community.
In this paper, the authors introduce a novel quantization framework known as LoRA-Fine-Tuning-aware Quantization (LoftQ). This framework is specifically tailored for pre-trained models that necessitate quantization and LoRA fine-tuning. The framework actively combines low-rank approximation, working in conjunction with quantization to jointly approximate the original high-precision pre-trained weights.
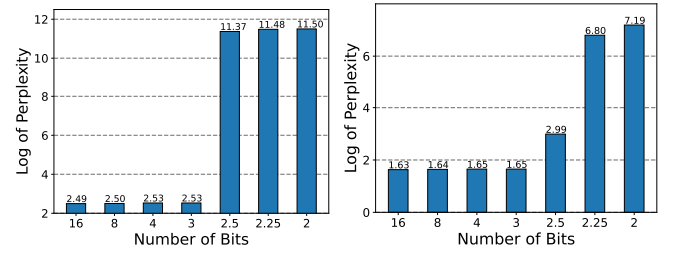
The above image demonstrates QLoRA performance with different bits. Left: QLoRA initialization of LLAMA-2-13b on WikiText-2. Right: Apply QLoRA to LLAMA-2-13b on WikiText-2 language modelling task. Smaller perplexity indicates better performance.
Quantization Methods. We apply two quantization methods to demonstrate LoftQ is compatible with different quantization functions:
• Uniform quantization is a classic quantization method. It uniformly divides a continuous interval into 2N categories and stores a local maximum absolute value for dequantization.
• NF4 and its 2-bit variant NF2 are quantization methods used in QLoRA. They assume that the high-precision values are drawn from a Gaussian distribution and map these values to discrete slots that have equal probability.
We perform 2-bit and 4-bit quantization on all models, achieving compression ratios of 25-30% and 15-20% at the 4-bit and 2-bit levels, respectively. All the experiments are conducted on NVIDIA A100 GPUs.
The evaluation of their quantization framework is carried out through extensive experiments on various downstream tasks, including NLU, question answering, summarization, and NLG. The results of these experiments demonstrate that LoftQ consistently surpasses QLoRA across all precision levels. For example, with 4-bit quantization, they attain a 1.1 and 0.8 improvement in Rouge-1 for XSum and CNN/DailyMail, respectively. As the field of NLP continues to advance, it is expected that further innovations and optimizations will help bridge the gap between the immense potential of PLMs and their practical deployment, benefiting a wide range of applications and users.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Source link