



Transformer models already trained can execute various downstream tasks with excellent performance before being used as model inference services. Such model inference services, however, may raise privacy issues. For instance, GitHub Copilot, a code-generating engine adapted from pre-trained GPT weights, requires either user to disclose their code prompts to the service provider for code generation or the service provider to make the Copilot’s trained weights—which are company proprietary—available to users. A possible solution is provided by Secure Multi-Party Computation (MPC), which protects user data and model weights during inference. The MPC’s vanilla Transformer inference calculation, however, is too sluggish. For example, BERTBASE runs in around one second without MPC but in about sixty seconds with MPC.
Previous research on convolutional neural networks (CNNs) has demonstrated that the inference process in MPC may be sped up by substituting computational approaches with quicker approximations (we refer to them as MPCfriendly approximations). However, using a straightforward replacement method significantly lowers the model’s quality. They begin by addressing the research issue in this paper: How can privacy-preserving Transformer model inference be carried out in MPC while still being quick and efficient? They specifically offer a method for employing MPC to carry out Transformer model inference while protecting privacy. Their straightforward and efficient approach allows for various Transformer weights and MPC-friendly approximations. They look at a brand-new, two-stage MPC technique for rapid transformer inference. By incorporating knowledge from existing private inference techniques for CNNs, they show how using MPC-friendly approximations may aid in speeding up Transformer models. They benchmark the transformer inference process using an MPC system and find that the GeLU and Softmax functions are the key bottlenecks. They are replaced by pre-made, MPC-friendly approximations, which substantially speed up the process. The second stage is on enhancing the quick approximated Transformer’s efficiency. They demonstrate that the fast approximated architecture is needed more than just training, in contrast to prior techniques.
There are two likely reasons: (1) Many MPC-friendly approximations make training models more difficult. For instance, while quadratic functions are quick in MPC, deep neural networks struggle with the gradient explosion problem they generate. (2) Downstream datasets typically only include a small quantity of data needed to train a suitable model using cross-entropy loss, for example, Zhang & Sabuncu; Hinton et al. They apply the knowledge distillation (KD) framework to address these two issues. First, KD can simplify the model training process by matching intermediate representations between the teacher and student models. In particular, earlier research has demonstrated that intermediate supervision can help to solve the gradient explosion issue. The layer-wise distillation is provided, and the input Transformer model is formulated as the teacher and the estimated Transformer model as the student in their use case. Additionally, earlier research has demonstrated that KD is data-efficient. They demonstrate empirically that this characteristic enables the approximated Transformer model to perform well when learning from limited downstream datasets. Their strategy. They develop MPCFORMER in this study, a simple framework for quick, effective, and private Transformer inference. Many trained Transformer models and MPC-friendly approximations are compatible with MPCFORMER. The bottleneck functions in the input Transformer model are first replaced with the provided MPC-friendly approximations.
The resultant approximated Transformer model has a quicker inference time in the MPC scenario. The estimated Transformer model is then subjected to knowledge distillation utilizing the input performant Transformer model as the teacher. The approximated Transformer model can learn effectively with downstream datasets thanks to intermediary supervision and the data efficient property. To achieve fast inference speed and high ML performance concurrently, the model provider can employ the distilled approximated Transformer on top of an MPC engine, such as Crypten, for private model inference service. Figure 1 displays the MPCFORMER system’s overall process.
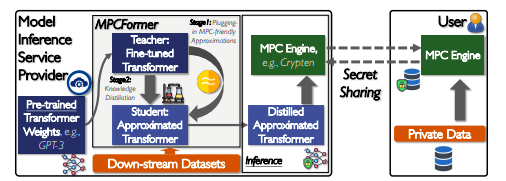
They provide three distinct contributions.
1. They suggest MPCFORMER, a two-stage framework that allows several MPC-friendly approximations and trained Transformer models to be inserted, enabling quick and effective private Transformer model inference with MPC.
2. By integrating their framework with an MPC system, MPC-friendly approximations, and trained Transformer models, they increase the speed of Transformer inference. They create a new, quicker, and MPC-friendly approximation of the Softmax function in the process.
3. They thoroughly assess the framework using trained Transformers and plugged-in approximations in the MPC environment. They achieve comparable ML performance to BERTBASE with a 5.3 speedup on the IMDb benchmark. With a 5.9 speedup, they attain ML performance similar to BERTLARGE. They accomplish 97% of the performance of BERTBASE with a 2.2 speedup on the GLUE benchmark. When connected to other trained Transformer models, such as RoBERTaBASE, MPCFORMER is also effective.
Check out the Paper and Code. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Source link
